什么是事物?
相信你已经对事物非常了解,而且有一个特别经典的案例,你一定熟知——银行转账
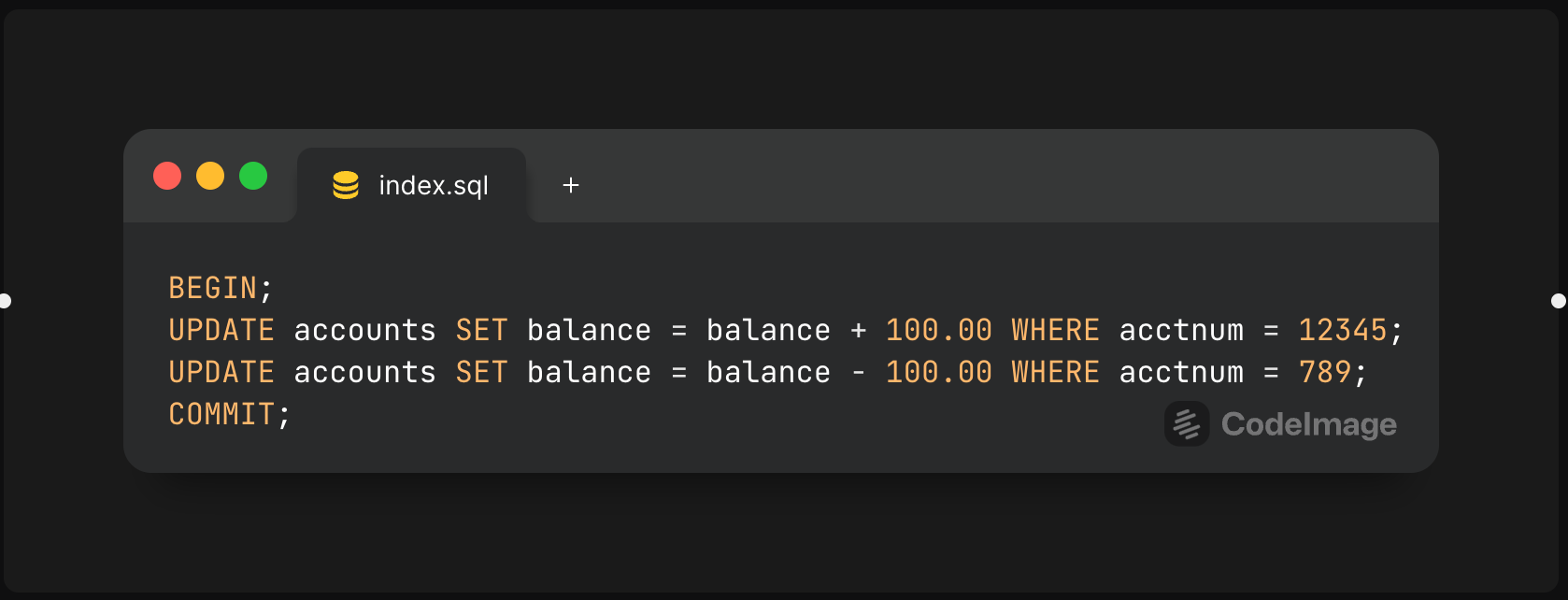
针对这个案例,我们肯定希望两个更新要么同时发生,要么都不发生。这就是原子性所保证的——``` 整个事务要么作为一个单元成功,要么作为一个单元失败。```
虽然原子性为单个事务提供了重要保障,但当你有多个事务并发运行时,隔离性保障就变得重要起来。假设我们有这样一个场景:一位用户执行了上述转账的场景,在该事务处理过程中但尚未提交之前,另一个人执行了查询语句``` select balance from accounts where acctnum=12345 。``` 这个查询将返回什么结果?它在第一个更新之前还是之后执行是否重要?
这正是隔离级别需要解决的问题—— 并发事务和查询如何相互影响。你可以看到为什么隔离可能比原子性更复杂——并发事务相互作用的方式更多。那么让我们看看数据库社区是如何处理隔离问题的。
SQL 92 中的事物隔离级别
事务隔离级别在ANSI SQL 92中被正式标准化。ANSI委员会首先定义了隔离的逻辑理想状态。按照他们的定义,理想的隔离状态是,
当你有多个事务同时发生时,数据库的最终状态是可以通过不并发而是顺序运行这组事务来实现的。它没有规定或要求任何特定的顺序,只是说必须存在一种可能的顺序。
这种隔离级别称为“可串行化”(Serializable),因为它保证存在一种能够产生相同结果的事务串行排序。它让你可以将数据库视为一个接一个发生的原子事务。
说实话,“可串行化”在正确性方面是绝对的黄金标准,因为它极大的简化了对并发场景的控制,你不需要担心所有这些事务交错执行的方式,因为永远都是按先来后到的按序执行。
但是这种隔离级别过于理想化,甚至是不切实际。 所以又引发了其他隔离级别的诞生。同时针对由于没有采用Serializable 导致可能遇到的奇怪结果,进行了一些异常定义。

各种数据库根据自己对性能和正确性需求的平衡选择如何实现这些隔离级别。
例如,在PostgreSQL中,默认情况下使用 **读已提交** 作为默认隔离级别,但它也支持通过使用特定配置来实现更高级别的隔离。而MySQL则有其独特的方式来处理这些问题和提供各种隔离选项。开发者应该根据应用程序的具体需求和数据库特性选择最合适的隔离策略。
脏读 Dirty Reads
“”“
当一个事务能够看到另一个未提交事务所做的更改时发生。
”“”
“Read Uncommitted”,最低级别的隔离,有可能会发生“脏读”。意味着读取尚未提交的数据。此时如果一个事务还没有被提交,它可能永远不会被提交。用户可能会改变主意,可能会有错误发生,数据库也可能崩溃。这里有一个简单的例子,假设我们有两个用户连接到同一个数据库,并且他们在差不多的时间各自进行操作:
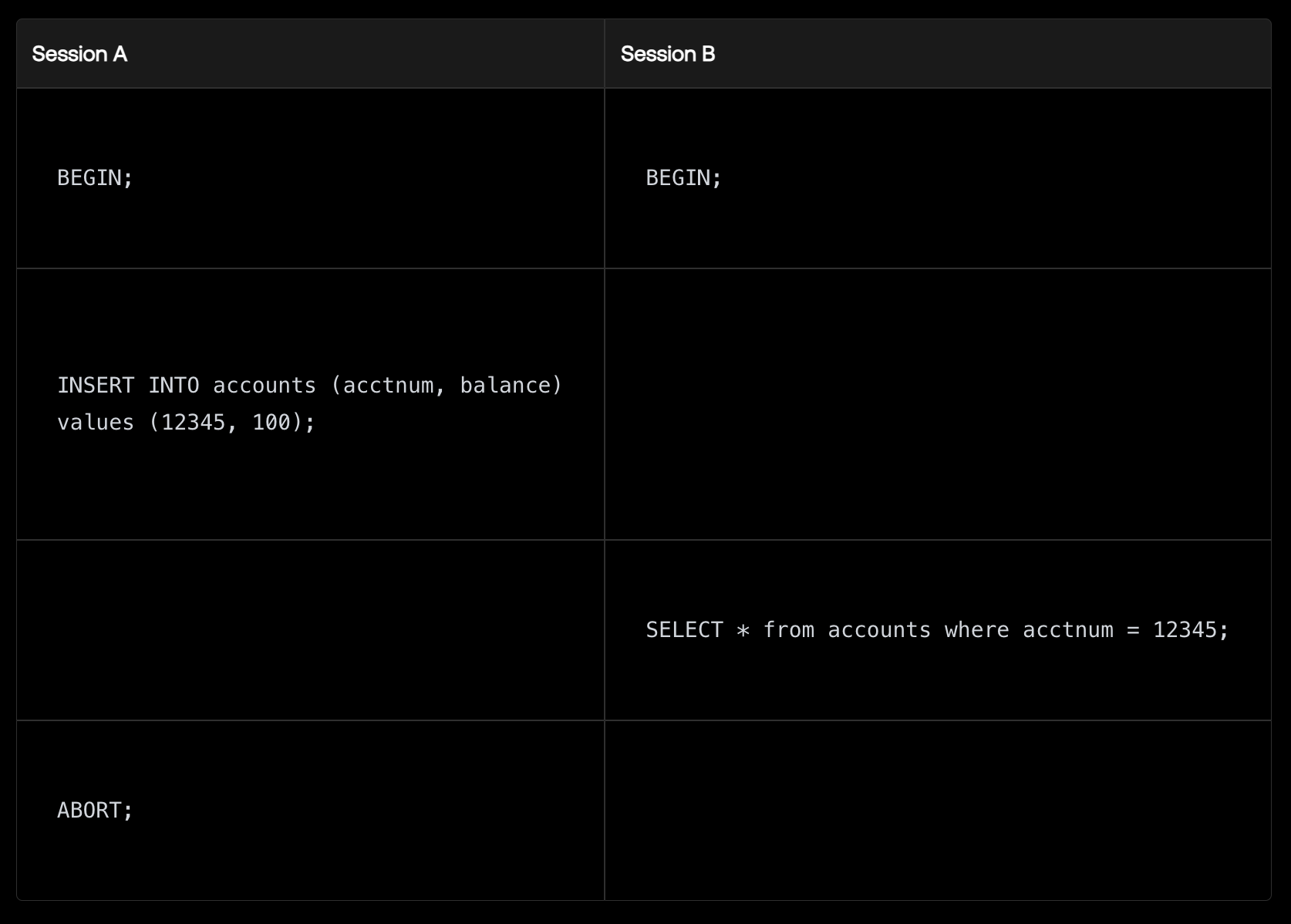
在“Read Uncommitted” 隔离级别下,如果这两个会话并发执行,会话B将看到一个不存在的账户和一个不存在的余额,最终导致业务错误。
看起来这个隔离级别毫无用处,但是在一些写入密集型的场景中还是可以使用的。当然很多数据库压根就不支持Read Uncommitted,比如Postgres。
不可重复读 Non-repeatable Reads
不可重复读取意味着如果在一个事务之间提交了并行会话,则一个事务中的相同查询可能会返回不同的结果。
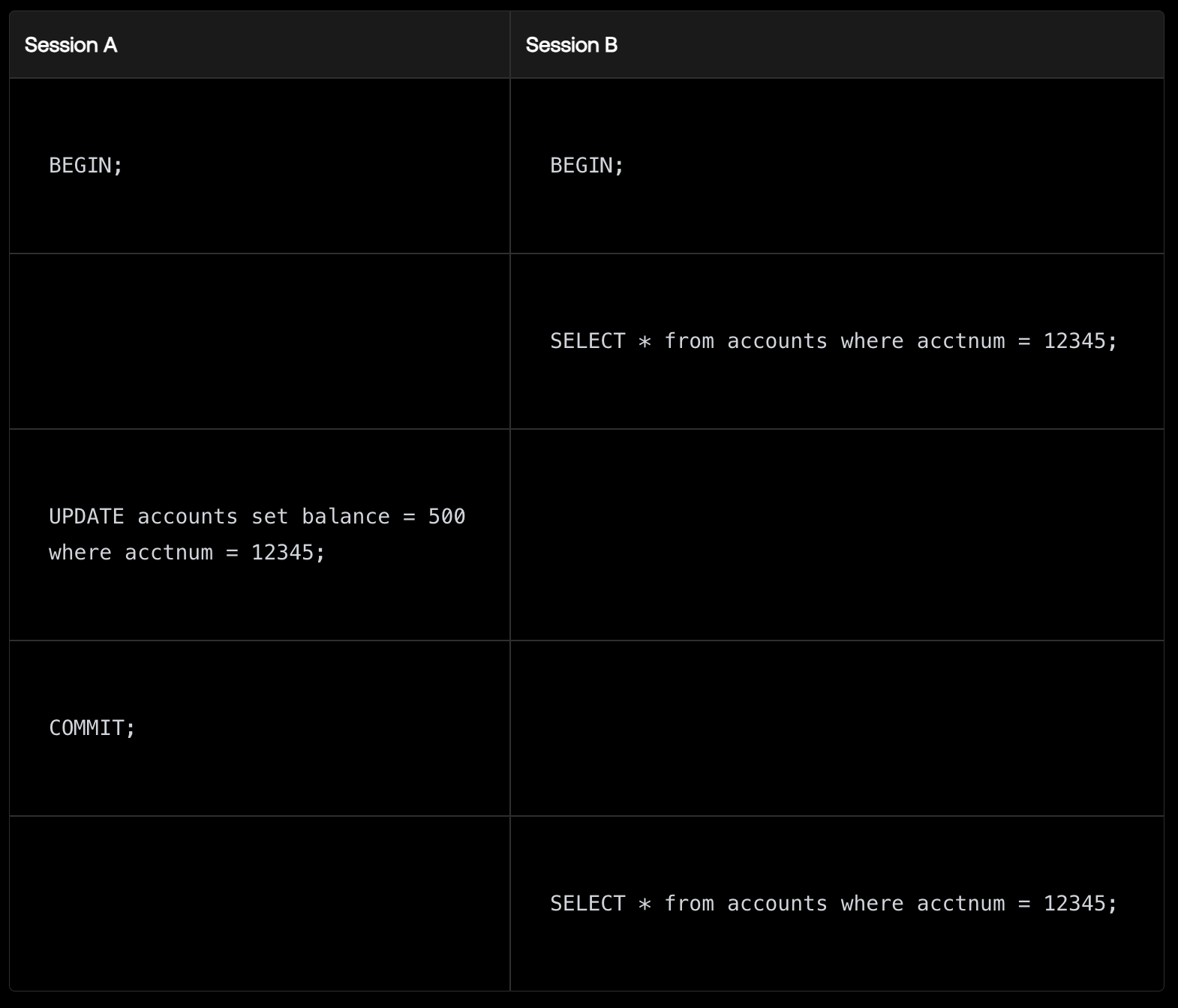
在“已提交读”隔离级别下,会话B中事务的第一次查询将返回与第二次查询不同的结果,因为会话A中的事务在两次查询之间已经提交了。从它们反映了数据库持久状态的角度来看,这两个结果都是“正确”的,但它们是不同的。你可能会思考,“这为什么会成为问题呢”?
问题在于,在一个单独的事务中进行多次相同查询却得到不同结果可能会违反应用程序对数据一致性的预期。例如,在财务报表或者重要决策支持系统中,如果数据在分析过程中发生变化,可能导致错误或者混淆。不可重复读可能使得事务不能准确地反映其开始时刻的数据状态,这对于需要高度数据一致性保证的应用来说是无法接受的。
有几种方法可以在不改变隔离级别的情况下解决这个问题。例如:
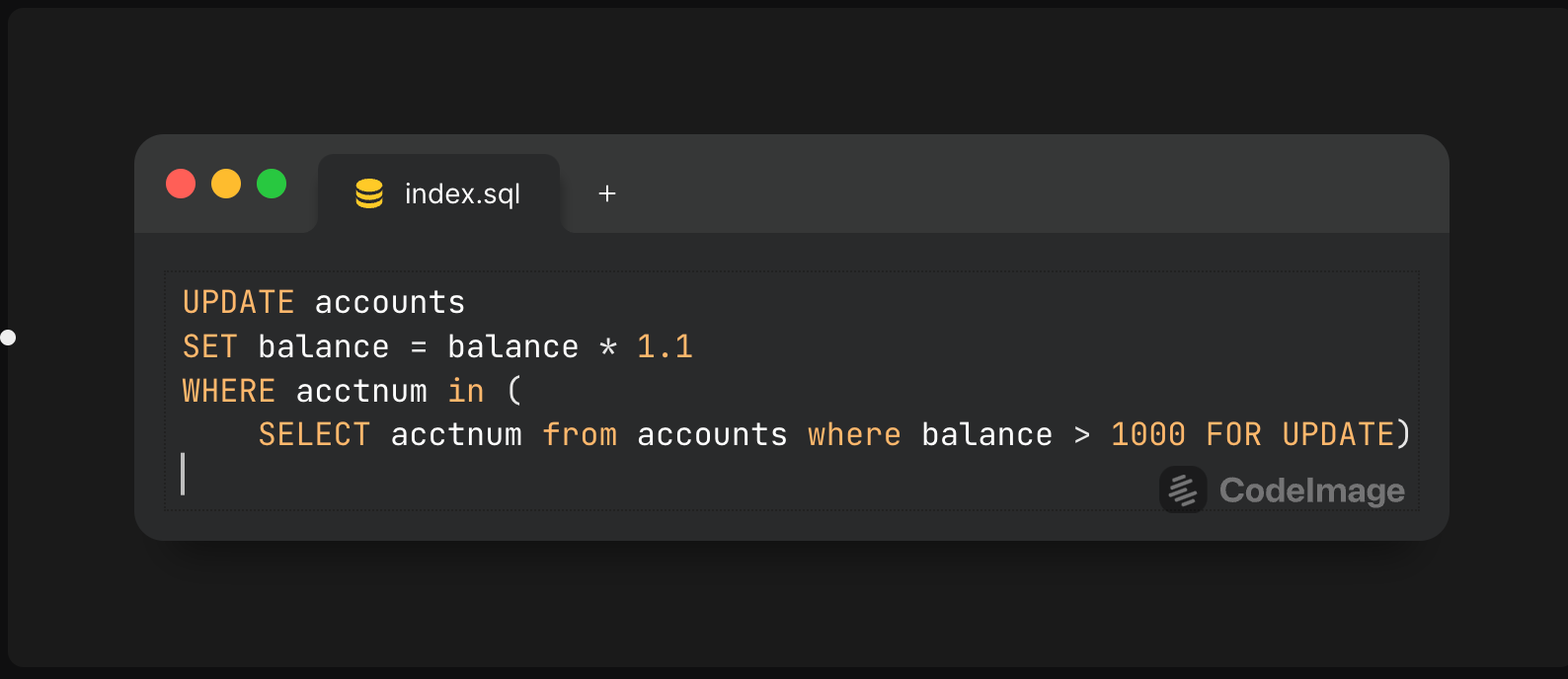
**SELECT…FOR UPDATE** 锁定了它选择的那些行。在这个例子中,其他会话在更新进行时将无法更新任何账户中的余额,从而防止了数据不一致性。当然,在这一点上,你需要权衡锁带来的性能影响与使用更高隔离级别带来的影响。
幻读 Phantom Reads
在"不可重复读"的异常情况下,你会看到在你的事务开始时已经存在的 ```行``` 发生了变化。相比之下,在"幻读"的异常情况下,主要是看到那些在事务开始时 不存在的 ```新行``` 突然在事务中途出现。

在“可重复读”隔离级别下,会话B中的两次查询将显示账户789的相同余额。因为在会话A中所做的更新对会话B来说是不可见的。然而,第二次查询也会包含由会话A创建的账户12345。这就是一个新行突然在事务中间出现。
这意味着会话B将产生一个不一致的报告——既因为它有两个返回了不同结果的查询,也因为第二次查询显示了会话A插入的数据,但没有显示它更新的数据。
值得注意的是,当一个并发会话进行更新操作导致新行匹配到一个查询时,你也可能遇到幻读现象。例如,如果账户789原先有-300的余额,而会话A将其更新到500,则在第二次查询时会话B能看到它,但在第一次查询时看不到。
总结
以上就是本文第一部分针对SQL92中定义的隔离级别进行整理总结了一下,以及他们对应解决的问题。
SQL92隔离级别有很多优点——它们是标准的,不太难以理解,并且为开发者在设计中做出好的决策提供了实用的工具。
在后续的文章,将会介绍SQL92 定义的事物隔离级别存在什么问题,以及PG/MYSQL和Oracle这些主流数据库又是如何实现事物隔离级别的。
尽请期待~