RAG
检索增强生成”(Retrieval-Augmented Generation, 简称RAG)。这项技术是为了解决大型语言模型(LLMs)虽然在庞大的数据集上进行训练,但并未针对特定用户数据进行优化的问题。
RAG通过将用户自己的数据添加到大型语言模型已有的数据中来解决这个问题。在相关文档中,你会经常看到提及RAG。
具体来说,在RAG中,你需要先加载并准备好你自己的数据,使之可以被查询或者说是“索引”。当用户发起查询时,这些索引会筛选出最相关的上下文信息。然后,这些上下文信息连同用户查询和一个提示(prompt)一起送到大型语言模型里去处理。最后,语言模型根据这些信息提供一个响应。
即使你正在构建的是一个聊天机器人或者代理服务,了解如何使用RAG技术将数据整合进你的应用也是非常重要的。
简而言之,RAG允许开发者将他们独有的、特定领域或业务相关的数据集成入预训练好的语言模型中,从而提高该模型在特定任务上处理问题时的准确性和相关性。
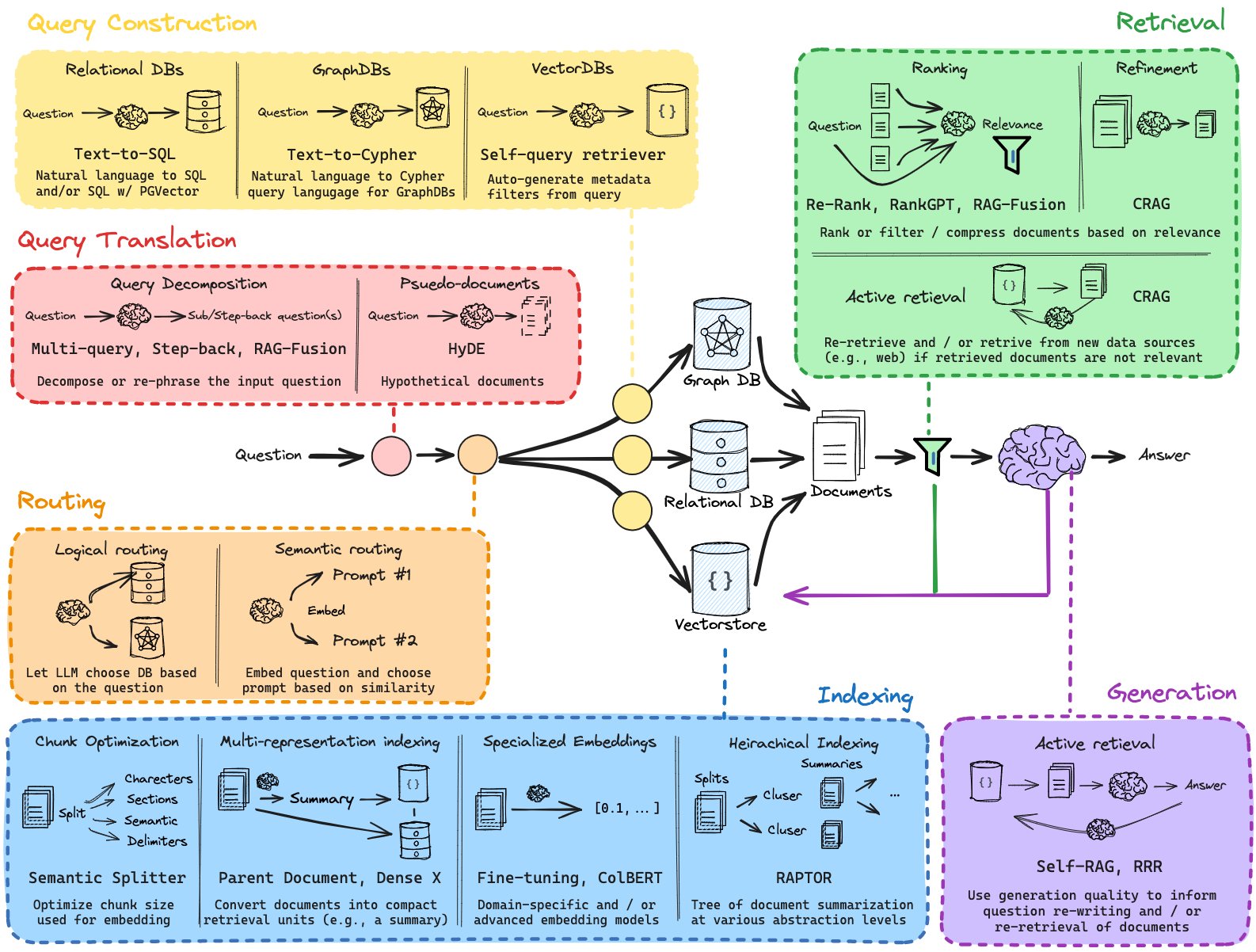
RAG的五个关键步骤
在使用检索增强生成(RAG)技术构建应用程序时,有五个关键阶段需要理解和实现。下面我会用中文逐一解释这些阶段:
1. 加载(Loading)
加载指的是将你的数据从其存储位置导入到你的处理流程中。数据可能存储在文本文件、PDF、其他网站、数据库或者通过API获取。
2. 索引(Indexing)
索引意味着创建一个能够查询数据的数据结构。对于大型语言模型来说,这几乎总是意味着要创建向量嵌入——即数据含义的数值表示,以及许多其他元数据策略,使得可以容易地准确找到上下文相关的数据。
3. 存储(Storing)
一旦你的数据被索引之后,你几乎总是需要存储你的索引和其他元数据,以避免重复进行索引操作。
4. 查询(Querying)
对于任何给定的索引策略,都有许多方法可以利用大型语言模型和LlamaIndex数据结构进行查询,包括子查询、多步骤查询和混合策略等。
5. 评估(Evaluation)
评估是任何处理流程中至关重要的一步,它用来检查相对于其他策略或者在进行变更时流程的有效性。评估提供了客观衡量标准来判断响应查询速度、准确性和可靠性。

以上就是RAG技术中五个关键阶段的简要介绍。在实际开发过程中,了解并正确执行这些阶段对于构建高效、精确且响应快速的AI系统至关重要。